
This article is part of Quantide’s web book “Raccoon – Statistical Models with R“. Raccoon is Quantide’s third web book after “Rabbit – Introduction to R” and “Ramarro – R for Developers“. See the full project here.
The second chapter of Raccoon is focused on T-test and Anova. Through example it shows theory and R code of:
- 1-sample t-test
- 2-sample t-test and Paired t
- 1-way Anova
- 3-way Anova
- Unbalanced and Nested
This post is the third section of the chapter, about 1-way Anova.
Throughout the web-book we will widely use the package qdata, containing about 80 datasets. You may find it here: https://github.com/quantide/qdata.
|
1 2 3 4 5 6 7 |
require(nortest) require(car) require(ggplot2) require(dplyr) require(gridExtra) require(tidyr) require(qdata) |
Example: Tissues (1-way ANOVA)
Data description
Three quality inspectors of a plant, Henry, Anne, and Andrew (operators) measure the strenght of car seat tissues. The company managers want to test the reproducibility, between operators, of company’s measurement system.
The main goal of study is then to verify if operators’ measures are confrontable.
Each operator measured 25 pieces of car seat tissues.
Globally, 75 samples of tissue randomly chosen from the same production batch were measured.
Data loading
|
1 2 |
data(tissue) head(tissue) |
|
1 2 3 4 5 6 7 |
## Operator Strength ## 1 Anne 11.30 ## 2 Anne 10.62 ## 3 Anne 10.36 ## 4 Anne 10.23 ## 5 Anne 10.42 ## 6 Anne 12.64 |
|
1 |
str(tissue) |
|
1 2 3 |
## 'data.frame': 75 obs. of 2 variables: ## $ Operator: Factor w/ 3 levels "Andrew","Anne",..: 2 2 2 2 2 2 2 2 2 2 ... ## $ Strength: num 11.3 10.6 10.4 10.2 10.4 ... |
Anne, Henry, and Andrew)
Descriptives
Plot of Strengt with Operator factor variable in abscissa:
|
1 2 3 4 5 6 7 |
tissue_mean <- tissue %>% group_by(Operator) %>% summarise(Strength=mean(Strength)) ggp <- ggplot() + geom_point(data = tissue, mapping = aes(x=Operator, y=Strength), colour="darkblue") + geom_line(data=tissue_mean, mapping = aes(x=Operator,y=Strength), colour="red", group=1) print(ggp) |
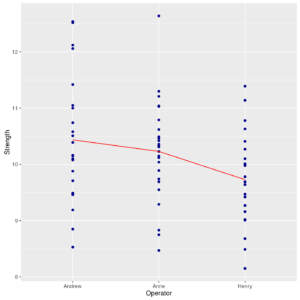
Stripchart of Strenght by Operator with connect line
A different way to show similar information is through a plot of univariate effects:
|
1 |
plot.design(Strength ~ Operator, data = tissue) |
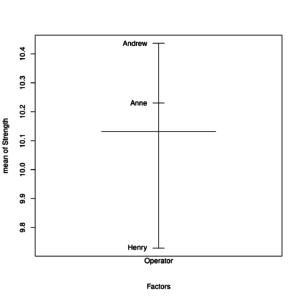 Plot of univariate effects of Operator on Strenght
Plot of univariate effects of Operator on Strenght
This plot shows the mean for each level of grouping factor compared to the grand mean (the center wider line).
Inference and models
Now we will try models with different contrast types.
Initially the model with default contrasts will be fitted to data, then the contr.sum and the contr.helmert contrast models will be shown.
Default contrasts:
|
1 |
options("contrasts") |
|
1 2 |
## $contrasts ## [1] "contr.treatment" "contr.poly" |
|
1 2 3 |
options(contrasts = c("contr.treatment", "contr.poly")) fm_treatment <- aov(Strength~Operator, data = tissue) summary(fm_treatment) |
|
1 2 3 4 5 |
## Df Sum Sq Mean Sq F value Pr(>F) ## Operator 2 6.62 3.31 3.851 0.0258 * ## Residuals 72 61.90 0.86 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 |
|
1 |
summary.lm(fm_treatment) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
## ## Call: ## aov(formula = Strength ~ Operator, data = tissue) ## ## Residuals: ## Min 1Q Median 3Q Max ## -1.9064 -0.5482 -0.0388 0.4656 2.4100 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 10.4364 0.1854 56.280 < 2e-16 *** ## OperatorAnne -0.2064 0.2622 -0.787 0.43384 ## OperatorHenry -0.7076 0.2622 -2.698 0.00868 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 0.9272 on 72 degrees of freedom ## Multiple R-squared: 0.09663, Adjusted R-squared: 0.07154 ## F-statistic: 3.851 on 2 and 72 DF, p-value: 0.02577 |
aov()’s predefined output gives a global p-value of 0.0258 on Operator effect.
Note that summary.lm() shows the aov resulting object fm_treatment as if it simply were an lm-type object.
From its output, Andrew’s mean appears significantly different from 0 (\(beta_0\) = 10.4364, p = 2e-16),
Henry seems significantly different from Andrew (0.7076 lesser, p-value=0.00868), whereas Anne’s seem not significantly different from Andrew (0.2064 lesser, p-value=0.43384).
Instead of summary() and summary.lm(), summary.aov() and summary() may be used, obtaining the same outputs:
|
1 2 |
fm_treatment <- lm(Strength~Operator, data = tissue) summary.aov(fm_treatment) |
|
1 2 3 4 5 |
## Df Sum Sq Mean Sq F value Pr(>F) ## Operator 2 6.62 3.31 3.851 0.0258 * ## Residuals 72 61.90 0.86 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 |
|
1 |
summary(fm_treatment) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
## ## Call: ## lm(formula = Strength ~ Operator, data = tissue) ## ## Residuals: ## Min 1Q Median 3Q Max ## -1.9064 -0.5482 -0.0388 0.4656 2.4100 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 10.4364 0.1854 56.280 < 2e-16 *** ## OperatorAnne -0.2064 0.2622 -0.787 0.43384 ## OperatorHenry -0.7076 0.2622 -2.698 0.00868 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 0.9272 on 72 degrees of freedom ## Multiple R-squared: 0.09663, Adjusted R-squared: 0.07154 ## F-statistic: 3.851 on 2 and 72 DF, p-value: 0.02577 |
In this sense, aov(),lm() and their resulting objects are substantially interchangeable.
Now let’s see what changes if constrasts settings are modified. The first contrast setting is contr.sum:
|
1 2 3 |
options(contrasts = c("contr.sum", "contr.poly")) fm_sum <- aov(Strength~Operator, data = tissue) summary(fm_sum) |
|
1 2 3 4 5 |
## Df Sum Sq Mean Sq F value Pr(>F) ## Operator 2 6.62 3.31 3.851 0.0258 * ## Residuals 72 61.90 0.86 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 |
|
1 |
summary.lm(fm_sum) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
## ## Call: ## aov(formula = Strength ~ Operator, data = tissue) ## ## Residuals: ## Min 1Q Median 3Q Max ## -1.9064 -0.5482 -0.0388 0.4656 2.4100 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 10.13173 0.10706 94.635 <2e-16 *** ## Operator1 0.30467 0.15141 2.012 0.0479 * ## Operator2 0.09827 0.15141 0.649 0.5184 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 0.9272 on 72 degrees of freedom ## Multiple R-squared: 0.09663, Adjusted R-squared: 0.07154 ## F-statistic: 3.851 on 2 and 72 DF, p-value: 0.02577 |
The interpretation of the contr.sum coefficients is not very simple: contrasts are the \(k-1\) differences (where \(k\) is the number of factor levels) between each level and a reference level; the resulting estimated coefficients contain the differences of each level mean (excluded the reference level) with respect to the grand mean; in fact, the model intercept is equal to grand mean.
aov(), however, gives the same results obtained with default contrasts.
Now let’s change contrast settings by selecting Helmert contrasts
|
1 2 3 |
options(contrasts = c("contr.helmert", "contr.poly")) fm_helm <- aov(Strength~Operator, data = tissue) summary(fm_helm) |
|
1 2 3 4 5 |
## Df Sum Sq Mean Sq F value Pr(>F) ## Operator 2 6.62 3.31 3.851 0.0258 * ## Residuals 72 61.90 0.86 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 |
|
1 |
summary.lm(fm_helm) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
## ## Call: ## aov(formula = Strength ~ Operator, data = tissue) ## ## Residuals: ## Min 1Q Median 3Q Max ## -1.9064 -0.5482 -0.0388 0.4656 2.4100 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 10.1317 0.1071 94.635 < 2e-16 *** ## Operator1 -0.1032 0.1311 -0.787 0.43384 ## Operator2 -0.2015 0.0757 -2.661 0.00959 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 0.9272 on 72 degrees of freedom ## Multiple R-squared: 0.09663, Adjusted R-squared: 0.07154 ## F-statistic: 3.851 on 2 and 72 DF, p-value: 0.02577 |
Helmert’s contrasts are even more complex than the others; they analyze:
- Initially, the difference between first level mean and the second level mean
- Then, the difference between the mean of first two (pooled) levels and the third level mean
- Then, the difference between the mean of first three (pooled) levels and the fourth level mean
- And so on for \(k-1\) contrasts
The main advantage of using Helmert contrasts is that they are orthogonal; the tests on linear model coefficients are then stocastically independent: the Type I and Type II error rate for the tests on Helmert coefficients are unrelated. The main disavantage, of course, is their complexity in coefficients explanations.
Now, let’s restore predefined contrasts:
|
1 |
options(contrasts = c("contr.treatment", "contr.poly")) |
Summarizing the results just seen about contrasts:
contr.treatmentmakes easier to read results, but the tests on coefficients are NOT independentcontr.summakes NO independent tests on coefficients, but compares pairs of means; also, the coefficients represent the distance of level’s mean with respect to grand mean, however they are not always easily interpretablecontr.helmertmakes independent tests on coefficients, but the coefficients are more difficult to interpret- anyway, until now, the global ANOVA (
aov())results are always the same:aov()analyzes effects globally, not single means
Residuals analysis
By plotting a model object (lm or aov) up to six residuals diagnostic plots may be shown.
By default, the plot() method applied on a model object shows four graphs:
- A plot of raw residuals against fitted values
- A Normal Q-Q plot on standardized residuals
- A scale-Location plot of \(sqrt{vert std. residuals vert}\) against fitted values. Here, \(std. residuals\) means raw residuals divided by \(hatsigma cdot sqrt{1-h_{ii}}\), where \(h_{ii}\) are the diagonal entries of the “hat” matrix (see Appendices chapter).
- A plot of standardized Pearson residuals against leverages. If the leverages are constant (as is the case in the balanced design of this example) the plot uses factor level combinations instead of the leverages for the x-axis.
The next lines of code split the graphical device in 4 areas (2 x 2) and plot diagnostic graphs in only one display
|
1 2 3 |
op <- par(mfrow = c(2, 2)) plot(fm_treatment) par(op) |
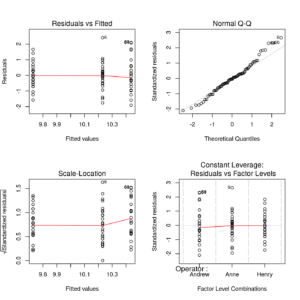
Compound diagnostic residual plot of Strenght Vs. Operator ANOVA model
The last line of above code restores the graphical device.
The residual plots confirm that normality and homoscedasticity assumptions are met, and no outliers appear. This confirms the model results.

[…] post Raccoon | Ch 2.3 – 1-way Anova appeared first on Quantide – R training & […]
[…] article was first published on R blog | Quantide – R training & consulting, and kindly contributed to […]